PaperNote-Pixel2Mesh(草稿)
序
Title:Pixel2Mesh:从单个RGB图像生成3D网格模型
仅用作个人理解与梳理, 如有错误, 还请各位同学指正.
Introduction
本文沿着单幅图像重建(single image reconstruction)的方向,提出了一种从单幅彩色图像(single color image)中提取三维三角网格(3D triangular mesh)的算法。
相比与直接生成3D Mesh的方法,
我们的模型学习将网格从a mean shape到目标几何图形(target geometry),
具有如下优点:
- 深度网络更擅长预测残差,例如空间变形,而不是结构化输出,例如图形。
- 其次,一系列变形可以叠加在一起,这使得形状可以逐渐细化到细节。它还可以控制深度学习模型的复杂性和结果质量之间的权衡.
- 最后,它提供了将任何先验知识编码到初始网格的机会,例如拓扑。
挑战:
- 第一个挑战是如何在神经网络中表示一个本质上是不规则图形的网格模型,并且仍然能够有效地从以2D规则网格表示的给定彩色图像中提取形状细节。
- 在三维几何方面,我们直接在网格模型上建立基于图的完全卷积网络(GCN)[3,8,18],其中网格中的顶点和边直接表示为图中的节点和连接. 3D形状的网络特征编码信息保存在每个顶点上。通过前向传播,卷积层实现了相邻节点之间的特征交换,并最终回归了每个顶点的3D位置。
- 2D图像方面,我们使用类似VGG-16的体系结构来提取特征,因为它已经被证明在许多任务中都是成功的
- 为了在两者之间架起桥梁,我们设计了感知特征池层,允许GCN中的每个节点从其在图像上的2D投影中汇集图像特征,这些特征可以很容易地通过假设摄像机的固有矩阵来获得。感知特征池在几次卷积后启用一次来更新3D位置,因此来自正确位置的图像特征可以有效地与3D形状集成。
- 下一个挑战是如何有效地更新顶点位置以接近ground truth:
- 我们设计了一个图分解层(graph unpooling layer),它允许网络以较少的顶点开始,并在前向传播过程中增加顶点。
- 除了图分解层(graph unpooling
layer)之外,我们还使用
deep GCN enhanced by shortcut connections作为我们架构的主干,这使得更大的接受域(large receptive fields)能够支持global context和more steps of movements。
Loss function:
- 表面法线损失(surface normal loss),有利于光滑表面
- edge loss: 为提高召回率而鼓励网格顶点均匀分布的边损失
- laplacian loss: 以防止网格面彼此相交
Method
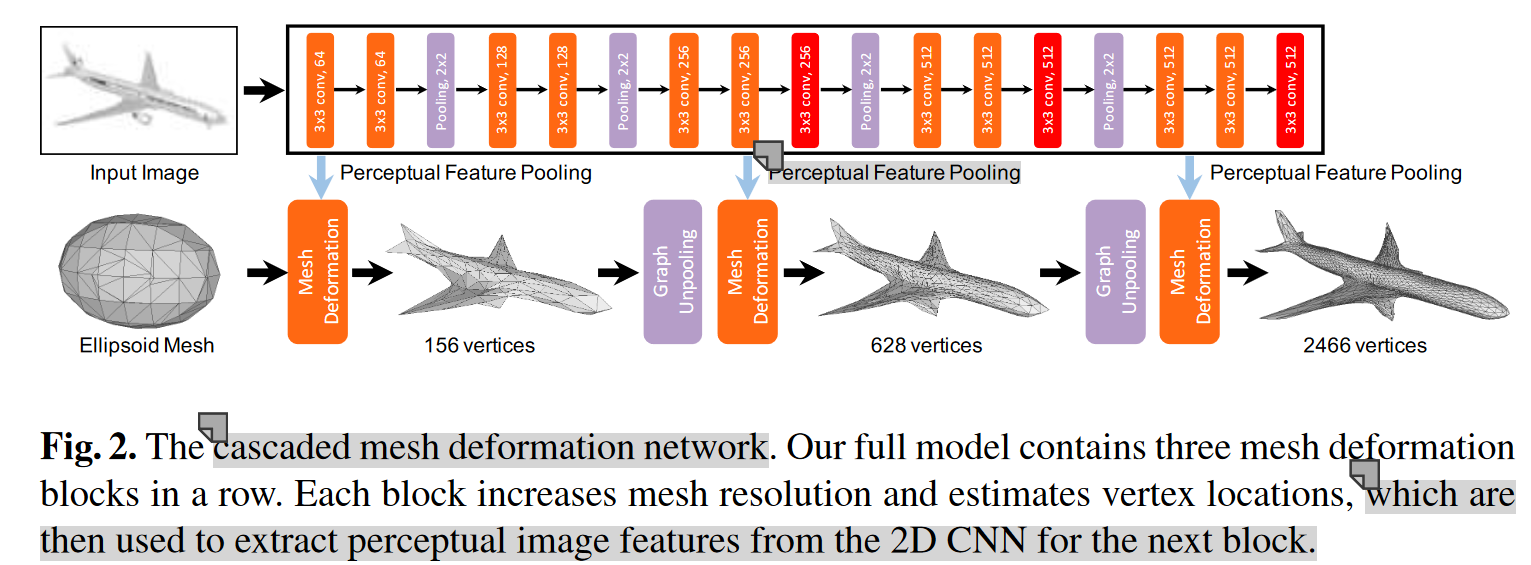
3.3 Initial ellipsoid: 初始椭球体
本模型不需要关于3D物体的任何prior knowledge, 将始终从初始椭圆变形,按平均大小放置在相机坐标中的公共位置. - 网格模型由Meshlab中的隐式曲面算法生成,包含156个顶点。
3.4 Mesh deformation block
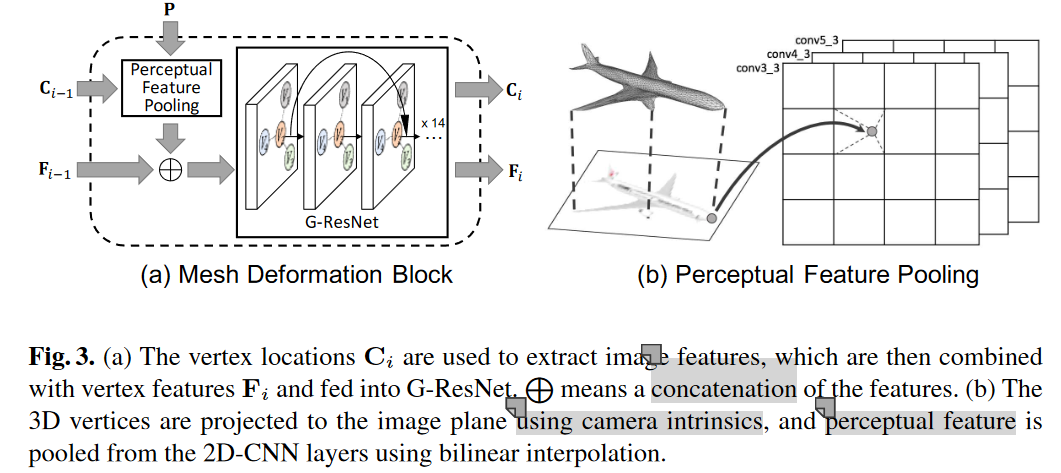
为了生成与输入图像中显示的物体一致的三维网格模型,the deformation block需要从输入图像中提取特征(P)。
在给定当前网格模型中顶点(\(C_{i−1}\))的位置的情况下,这通过图像特征网络(image fearture network)和感知特征池层(perceptual feature pooling layer)相结合来完成。
然后,将汇集的感知特征与附加在input graph(\(F_{i−1}\))的顶点上的3D形状特征连接起来,并馈送到一系列graph based ResNet(G-Resnet)中.
G-ResNet还产生每个顶点的新坐标(\(C_i\))和3D形状特征(\(F_i\))作为Mesh deformation block的输出.
Perceptual feature pooling layer
由于图像特征网络的广泛使用,我们采用VGG-16体系结构直到第53层作为图像特征网络.
该算法首先利用摄像机的内蕴函数(camera intrinsics)计算其在输入图像平面上的二维投影,然后利用双线性插值法从相邻的四个像素点集合特征.
具体地说,我们将从层‘Conv3_3’、‘Conv4_3’和‘Conv5_3’中提取的特征连接在一起,从而得到总维度为1280的感知特征(perceptual feature).
然后,将该感知特征与来自输入网格的128维3D特征串联,从而得到1408的总维度.
注意,在第一个块中,感知特征与三维特征(坐标)串联,因为在开始处没有学习的形状特征。
G-ResNet
在获得表示3D形状和2D图像信息的每个顶点的1408-dim特征之后,我们设计了一个基于图的卷积神经网络来预测每个顶点的新位置和三维形状特征. 这需要在顶点之间有效地交换信息
然而, 如公式1所示, ...影响效率
为了解决这个问题,我们建立了一个具有快捷连接的非常深的网络,并将其表示为G-ResNet - 在这项工作中,所有块中的G-ResNet具有相同的结构,由14个图残差卷积层和128个通道组成。G-ResNet块的序列产生新的128维3D特征。 - 有一个分支将额外的图形卷积层应用于最后一层要素,并输出顶点的3D坐标。
3.5 Graph unpooling layer
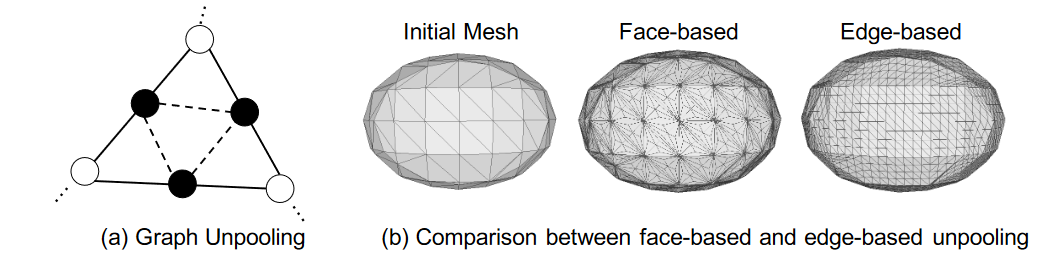
受计算机图形学中流行的网格细分算法的顶点添加策略的启发,我们在每条边的中心添加一个顶点,并将其与该边的两个端点相连(图4(A))。