Paper-note-3DGaussianSplatting
简介
Title: 3D Gaussian Splatting for Real-Time Radiance Field Rendering
Github链接: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
该博客说是笔记, 其实是翻译更准确一些. (机翻 仅供个人参考)
0 ABSTRACT
最近革命性地出现了用辐射场方法来进行多张照片或视频捕捉场景的新颖视角合成的工作。 然而,要获得高视觉质量,仍然需要昂贵的训练和渲染时间成本,而最近更快的方法不可避免地要牺牲速度来换取质量。 对于无边界和完整的场景(而不是孤立的对象)和1080p分辨率的渲染,目前没有任何方法可以达到实时显示率。 我们引入了三个关键元素,使我们能够在保持有竞争力的训练时间的同时实现最先进的视觉质量,重要的是,在1080p分辨率下实现高质量的实时(≥ 30 fps)新视图合成。
- 首先,从摄像机标定过程中产生的稀疏点开始,
我们用3D高斯图表示场景,保留了连续体积辐射场的理想性质,用于场景优化,同时避免了在空空间(空气)中不必要的计算
- 其次,我们对3D高斯进行交错优化/密度控制(interleaved
optimization/density
control),特别是优化各向异性协方差,以实现场景的准确表示
- 第三,我们开发了一种支持各向异性飞溅(anisotropic splatting)的快速可见性感知渲染算法,既加快了训练速度,又允许实时渲染。
1 INTRODUCTION
网格和点是最常见的3D场景表示,因为它们是显式的,非常适合基于GPU/CUDA的快速光栅化。 相比之下,最近的神经辐射场(NeRF)方法建立在连续的场景表示上,通常使用体积射线行进(volumetric ray-marching)来优化多层感知器(MLP),用于捕获场景的新视图合成。 类似地,迄今为止最有效的辐射场解决方案通过对存储在例如voxel/Hash Grid/Points中的值进行内插而建立在连续表示之上. 虽然这些方法的连续性质有助于优化,但渲染所需的随机采样成本很高,并且可能会导致噪声。 我们引入了一种结合了两个方面优点的新方法:我们的3D高斯表示允许以最先进的(SOTA)视觉质量和具有竞争力的训练时间进行优化.
我们的目标是允许实时渲染与多张照片捕获的场景,
并创建具有最优化时间的表示,与用于典型真实场景的最有效的先前方法一样快,
最近的方法实现了快速训练, 但是难以实现由当前SOTA
NeRF方法获得的视觉质量,即Mip—NeRF360,
其往往需要长达48小时的训练时间。
一些快速但质量较低的辐射场方法可以根据场景实现交互式渲染时间(每秒10—15帧),但在高分辨率下无法实现实时渲染。
我们的解决方案基于三个主要组件。
我们首先介绍了一种灵活的、富有表现力的3D高斯场景表示方法。 我们从与以前的NeRF类方法相同的输入开始,即,使用运动结构(SfM)校准的摄像机并使用作为SFM过程中产生的稀疏点云来初始化3D高斯线集。 与大多数需要多视图立体(MVS)数据的基于点的解决方案形成对比, 我们仅使用(Structure-from-Motion)SfM points作为输入即可获得高质量的结果。 请注意,对于NeRF合成数据集(NeRF-synthetic dataset),我们的方法即使使用随机初始化也能达到高质量。 我们表明,3D高斯是一个很好的选择,因为它们是一个可微分的体积表示,但它们也可以通过将它们投影到2D,并应用标准α—blending,使用等效的NeRF图像形成模型来非常有效地光栅化。
我们方法的第二个组成部分是优化3D高斯的属性-3D位置、不透明度α、各向异性协方差和球谐(SH)系数-与自适应密度控制(adaptive density control)步骤交织在一起,在优化过程中我们添加并偶尔移除3D高斯。优化过程产生了一个相当紧凑的、非结构化的和精确的场景表示(在所有的场景中大概产生了100万到500万Gaussians)
我们方法的第三个也是最后一个组件: 是我们的实时渲染解决方案,它使用了快速GPU排序算法,并受到了tile-based的光栅化(tile-based rasterization)的启发。However, thanks to our 3D Gaussian representation, we can perform anisotropic splatting that respects visibility ordering – thanks to sorting and αblending – and enable a fast and accurate backward pass by tracking the traversal of as many sorted splats as required.
总之,我们提供以下贡献:
- 引入各向异性3D高斯作为辐射场的高质量、非结构化表示
- 一种3D高斯属性的优化方法,与自适应密度控制交织,为捕获的场景创建高质量的表示
- 一种快速、可区分的GPU渲染方法,它是一种可分辨的方法,允许各向异性飞溅和快速反向传播,以实现高质量的新颖视图合成
2 RELATED WORK
Traditional Scene Reconstruction and Rendering
运动结构(Structure—from—Motion,SfM)的出现实现了一个全新的领域,在这个领域中,可以使用一组照片来合成新颖的视图。 SFM在相机校准过程中估计稀疏点云,最初用于3D空间的简单可视化。 随后的多视点立体(multi-view stereo)(MVS)在多年来产生了令人印象深刻的全3D重建算法 所有这些方法都将输入图像重新投影并混合到新的视图相机中,并使用几何来引导这种重新投影。 这些方法在许多情况下都产生了很好的结果,但当MVS生成不存在的几何形状时,通常不能完全从未重建的区域或“过度重建”中恢复。 最近的神经渲染算法大大减少了此类伪影,避免了在GPU上存储所有输入图像的巨大成本,在大多数方面都优于这些方法。
Neural Rendering and Radiance Fields
InstantNGP
Point-Based Rendering and Radiance Fields
基于点的方法有效地渲染disconnected和unstructured的几何样本(即,点云). 最简单的形式是point sample rendering, 光栅化具有固定大小的非结构化点集. 为此,它可以利用本地支持的图形API或GPU上的并行软件光栅化的点类型.
虽然对底层数据是真的,但点采样渲染会出现holes,会导致causes aliasing,并且strictly discontinuous。 Seminal work on high-quality point-based rendering addresses these issues by “splatting” point primitives with an extent larger than a pixel, e.g., circular or elliptic discs, ellipsoids, or surfels
最近人们对基于点的可区分渲染技术产生了兴趣,Points have been augmented with neural features and rendered using a CNN resulting in fast or even real-time view synthesis. 但是,它们仍然依赖于初始几何体的MVS,因此会继承其瑕疵,最明显的是在无特征/有光泽的区域或薄结构等困难情况下重建过度或不足。
基于点的α混合和NERF样式体绘制本质上共享相同的图像形成模型。
具体地说,颜色C由沿光线的体积渲染提供: 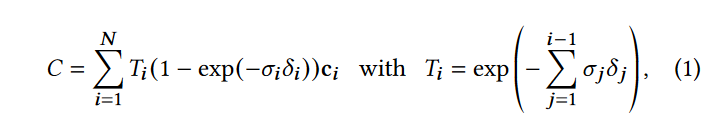 where samples of density \(σ\),
transmittance \(T\) , and color \(c\) are taken along the ray with intervals
\(δ_i\) .
where samples of density \(σ\),
transmittance \(T\) , and color \(c\) are taken along the ray with intervals
\(δ_i\) .
这可以重写为: 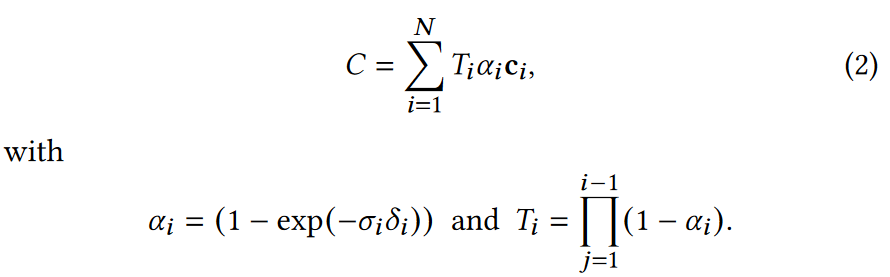
典型的基于神经点的方法通过混合与像素重叠的N个有序点来计算像素的颜色C:
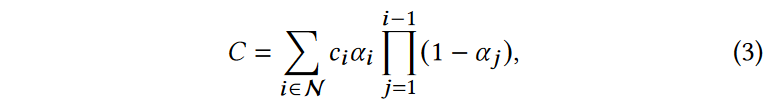 where \(c_i\) is the color of each
point and \(α_i\) is given by
evaluating a 2D Gaussian with covariance \(Σ\) multiplied with a learned per-point
opacity.
where \(c_i\) is the color of each
point and \(α_i\) is given by
evaluating a 2D Gaussian with covariance \(Σ\) multiplied with a learned per-point
opacity.
从方程2和等式3我们可以清楚地看到,成像模型是相同的。 然而,渲染算法有很大的不同。NeRF是隐含地表示空/占用空间的连续表示; 需要昂贵的随机采样来找到方程2中的样本,结果是噪声和计算费用。 相比之下,点是一种非结构化的离散表示,它足够灵活,可以创建、销毁和置换 这是通过优化不透明度和位置来实现的,如先前的工作所示,同时避免了全量表示(full volumertic representation)的缺点。
Pulsar实现了快速的球体光栅化,这启发了我们tile-based and sorting renderer。然而,考虑到上面的分析,我们希望在排序的splats上保持(近似)传统的α混合,以具有体积表示的优点.
我们的光栅化尊重可见性顺序,而不是它们的顺序无关的方法。 In addition, we backpropagate gradients on all splats in a pixel and rasterize anisotropic splats. 所有这些元素都有助于我们的结果的高视觉质量. 此外,上述先前的方法也使用CNN进行渲染,这导致时间不稳定。 Nonetheless, the rendering speed of Pulsar and ADOP(两个工作) served as motivation to develop our fast rendering solution.
在关注镜面效果的同时,基于漫反射点的神经点消散轨迹通过使用MLP克服了这种时间不稳定性,但仍然需要MVS几何作为输入。 这类最新的方法不需要MVS,也使用SH作为方向;然而,它只能处理一个对象的场景,并且需要掩码来初始化。 虽然对于小分辨率和低点计数来说速度很快,但目前还不清楚它如何扩展到典型数据集的场景 我们使用3D高斯图来更灵活地表示场景,避免了对MVS几何体的需要,并通过我们针对投影的高斯图的tile-based的渲染算法实现了实时渲染。
3 OVERVIEW
我们的方法的输入是一组静态场景的图像,连同相应的相机校准SfM, 通过该方法还可以获得一些稀疏点云. 根据这些点,我们创建了一组3D高斯,由位置(均值)、协方差矩阵和不透明度α定义,允许非常灵活的优化机制。 这导致了3D场景的相当紧凑的表示,部分原因是高度各向异性的体积分割(anisotropic volumetric splats)可以用来紧凑地表示精细结构。 按照标准做法,辐射场的方向外观分量(颜色)由球谐(SH)表示. 我们的算法继续创建辐射场表示通过3D高斯参数的一系列优化步骤,即,位置、协方差、α和SH系数与用于高斯密度的自适应控制的操作交织。 我们方法效率的关键是我们的tile-based的光栅化器这允许\(\alpha\)-blending of anisotropic splats,并由于快速排序而尊重可见性顺序。
4 DIFFERENTIABLE 3D GAUSSIAN SPLATTING
我们的目标是优化场景表示,允许从不带法线的稀疏(SfM)点集开始进行高质量的新颖视图合成. 要做到这一点,我们需要一个基元,它继承了可微体积表示的属性,同时是非结构化和显式的,以允许非常快的渲染。 我们选择3D高斯图,这是可微的,可以很容易地投影到2D-splats,允许快速的α混合渲染。
我们的表示与以前使用2D点的方法有相似之处并假设每个点都是is a small
planar circle with a normal。 考虑到SfM点的极端稀疏性,很难估计法线.
从这样的估计中优化非常嘈杂的法线将是非常具有挑战性的。
相反,我们将几何体建模为一组不需要法线的3D高斯。
我们的高斯是由世界空间中定义的以\(\mu\)为中心的全3D协方差矩阵Σ定义的: 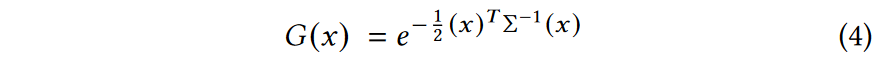 在我们的混合过程中,该高斯被乘以α。
在我们的混合过程中,该高斯被乘以α。
然而,我们需要将我们的3D高斯投影到2D以进行渲染。 Zwicker et
al.演示如何将此投影投影到图像空间。
给定观察变换W,摄像机坐标中的协方差矩阵\(Σ'\)被给出如下: 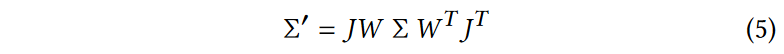 其中, J is the Jacobian of the affine approximation of the projective
transformation.。 Zwicker et al.
如果我们跳过Σ的第三行和第三列,我们得到了一个2×2的方差阵,它的结构和性质与以前的工作一样,就像从法线平面点开始一样.
其中, J is the Jacobian of the affine approximation of the projective
transformation.。 Zwicker et al.
如果我们跳过Σ的第三行和第三列,我们得到了一个2×2的方差阵,它的结构和性质与以前的工作一样,就像从法线平面点开始一样.
一种明显的方法是直接优化协方差矩阵Σ以获得表示辐射场的3D高斯。 然而,协方差矩阵只有当它们是半正定的时才具有物理意义。 对于我们的所有参数的优化,我们使用不容易约束的梯度下降来产生这样的有效矩阵,而更新步长和梯度可以非常容易地产生无效的协方差矩阵。
因此,我们选择了一种更直观、但具有同等表现力的表示来进行优化。3D高斯的协方差矩阵Σ类似于描述椭球体的形状。给定一个缩放矩阵S和旋转矩阵R,我们可以找到对应的Σ:
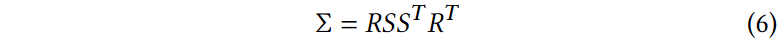
为了允许这两个因素的独立优化,我们将它们分开存储:用于缩放的3D向量S和表示旋转的四元数Q。它们可以简单地转换成它们各自的矩阵并组合,确保标准化Q以获得有效的单位四元数。
为了避免在训练过程中由于automatic
differentiation而产生的大量开销,我们显式地推导了所有参数的梯度。准确的导数计算详情载于附录A。
这种各向异性协方差的表示-适合优化-允许我们优化3D高斯以适应捕获场景中不同形状的几何形状,从而产生相当紧凑的表示。图3示出了这种情况

5 OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANS
我们方法的核心是优化步骤,它创建了一组密集的3D高斯图,准确地表示了用于自由视点合成的场景。 除了位置p、α和协方差Σ之外,我们还优化了代表每个高斯的颜色c的SH系数,以正确地捕捉场景的视点相关外观。 这些参数的优化与控制高斯密度的步骤交错,以更好地表示场景
5.1 Optimization
该优化是基于渲染结果图像并将其与捕获的数据集中的训练视图进行比较的连续迭代。 不可避免的是,由于3D到2D投影的模糊性,几何图形可能会被错误放置。 因此,我们的优化需要能够创建几何体,并在几何体定位错误的情况下销毁或移动几何体。 3D高斯分布的协方差参数的质量对于表示的紧凑性至关重要,因为可以用少量的大的各向异性的高斯分布来捕捉大的均匀区域
我们使用随机梯度下降技术进行优化,充分利用标准GPU加速框架,并根据最近的最佳实践为某些操作添加定制CUDA内核的能力。 特别是,我们的快速光栅化对于优化的效率至关重要,因为它是优化的主要计算瓶颈。
我们使用一个sigmoid激活函数来约束α在[0—1]范围内,并获得平滑梯度,以及基于类似原因的协方差尺度的指数激活函数。
我们将初始协方差矩阵估计为各向同性高斯矩阵,其轴线等于到最近三点的距离的平均值。
我们使用一个标准的指数衰减调度技术,类似于Plenoxels,但仅用于位置。
损失函数是L1与D-SSIM项相结合: 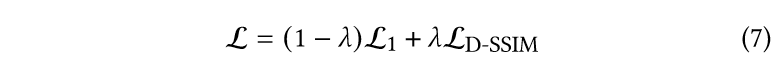
5.2 Adaptive Control of Gaussians
我们从SfM的初始稀疏点集开始,然后应用我们的方法自适应地控制单位体积上的高斯数量和它们的密度,使我们能够从初始稀疏的高斯集合到更密集的集合,更好地代表场景,并具有正确的参数。 After optimization warm-up, 我们densify every 100 iterations,并删除任何本质上透明的高斯,即\(α\)小于阈值\(ε_α\)。
我们对高斯的自适应控制需要填充空白区域。它关注的是缺少几何特征的区域(“欠重建”),但也关注高斯覆盖场景中大面积的区域(这通常对应于“过度重建”). 我们观察到两者都有很大的视图空间位置梯度。直观地说,这很可能是因为它们对应于尚未很好重建的区域,而优化试图推动高斯来纠正这一点。
由于这两种情况都是densification的很好候选者,所以我们用高于阈值\(τ_pos\)的视图空间位置梯度的平均幅度来致密高斯,在我们的测试中我们将其设置为0.0002。(we densify Gaussians with an average magnitude of view-space position gradients above a threshold \(τ_pos\), which we set to 0.0002 in our tests.)
对于处于重构不足区域的小高斯,我们需要覆盖必须创建的新几何。为此,最好是克隆高斯,只需创建一个相同大小的副本,并在位置梯度的方向移动它。
另一方面,在高方差区域中的大高斯需要被分割成较小的高斯。我们用两个新的高斯变换器代替这种高斯变换器,并将它们的尺度除以一个我们实验确定的因子φ = 1.6。我们还通过使用原始的3D高斯作为PDF样本来初始化它们的位置。
在第一种情况下,我们检测并处理增加Total Volume of the system和高斯数量的需要,而在第二种情况下,我们保留Total Volume,但增加高斯数量。
与其他体积表示类似,我们的优化可能会在靠近输入摄影机的浮动框中停滞不前;在我们的情况下,这可能会导致高斯密度的不合理增加。An
effective way to moderate the increase in the number of Gaussians is to
set the α value close to zero every N = 3000 iterators. 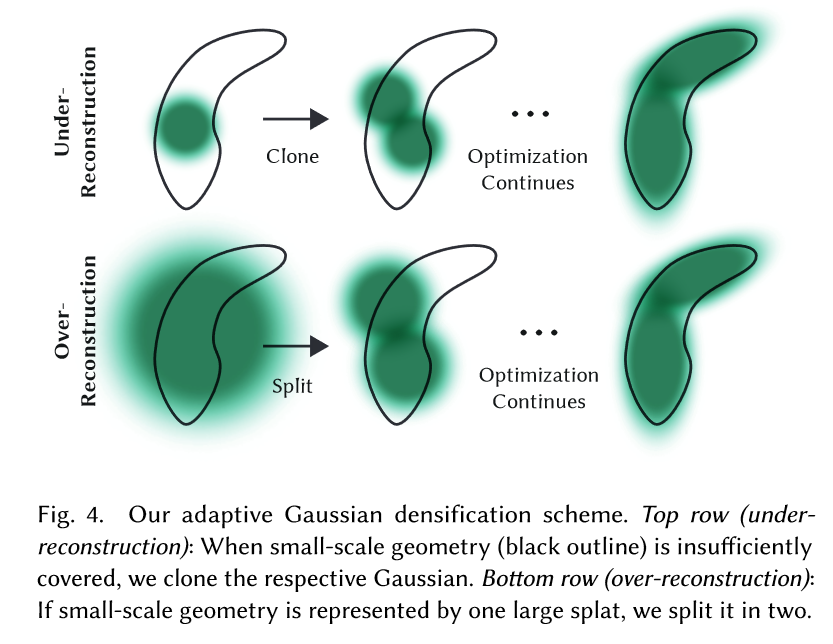
高斯可能会缩小或增长,并与其他高斯大部分重叠,但我们会周期性地删除在世界空间中非常大的高斯,以及在视图空间中有很大足迹(a big footprint)的高斯。这一策略导致了对高斯总人数的总体良好控制。
6 FAST DIFFERENTIABLE RASTERIZER FOR GAUSSIANS
Our goals are to have fast overall rendering and fast sorting to allow approximate α-blending – including for anisotropic splats – and to avoid hard limits on the number of splats that can receive gradients that exist in previous work.
为了实现这些目标,我们设计了一种tile-based的Gaussian splats光栅化器,其灵感来自于最近的软件光栅化方法 我们的快速光栅化器允许有效的反向传播任意数量的混合高斯与低的额外内存消耗,只需要一个恒定的开销每像素。 我们的光栅化流水线是完全可微的,并且给定到2D的投影可以光栅化各向异性的溅射类似于先前的2D溅射方法
我们的方法首先将屏幕分割成16×16个平铺,然后根据视锥和每个平铺来剔除3D高斯。具体地说,我们只保留了与视锥相交的99%可信区间的高斯。 此外,我们使用保护带(guard band)来平凡地拒绝(trivially reject)极端位置的高斯(即,那些平均值接近近平面而远离视锥的那些),因为计算他们的投影2D协方差将是不稳定的。
然后,我们根据它们重叠的tiles数量实例化每个高斯,并为每个实例分配一个键,该键结合了视图空间深度和瓦片ID。 然后,我们使用单个快速的GPU基数排序,根据这些键对高斯型进行排序 注意,没有额外的点的每像素排序,混合是基于该初始排序执行的。 因此,我们的α—混合在某些构型中是近似的。然而,这些近似值变得可以忽略不计,因为splats接近单个像素的大小。我们发现,这种选择极大地增强了训练和渲染性能,而不会在融合场景中产生可见的伪影。 在对高斯图进行排序后,我们通过识别拆分到给定图块的第一个和最后一个按深度排序的条目来为每个图块生成一个列表。 对于光栅化,我们为每个平铺启动一个线程块。每个块首先协作地将高斯分组加载到共享存储器中,然后对于给定的像素,通过从前到后遍历列表来累积颜色和α值,从而最大化数据加载/共享和处理的并行度增益。 当我们在一个像素中达到α的目标饱和度时,相应的线程停止。每隔一定时间查询切片中的线程,当所有像素都饱和时,整个切片的处理将终止.
在光栅化过程中,α的饱和度是唯一的停止准则。与之前的工作相反,我们不限制接收梯度更新的混合图元的数量。 我们强制执行这个属性,以允许我们的方法处理任意的,不同深度复杂度的场景,并准确地学习它们,而不必诉诸场景特定的超参数调整。 因此,在后向传递期间,我们必须在前向传递中恢复每个像素的混合点的完整序列。一种解决方案是在全局内存中按像素存储任意长的混合点列表. 为了避免隐含的动态内存管理开销,我们选择再次遍历pertile列表;我们可以重用前向传递的Gaussian和tile range的排序数组。为了便于梯度计算,我们现在将它们前后遍历。
遍历从影响图块中任何像素的最后一个点开始,并且再次协作地将点加载到共享内存中。此外,如果每个像素的深度低于或等于前向传递期间对其颜色作出贡献的最后一个点的深度,则每个像素将仅开始(昂贵的)重叠测试和处理。第二节中描述的梯度计算。4需要原始混合过程中每一步的累积不透明度值。我们可以通过在前向传递结束时仅存储总累积的不透明度来恢复这些中间不透明度,而不是在后向传递中遍历一个显式的逐渐缩小的不透明度列表。具体地说,每个点在正向过程中存储最终累积的不透明度α;我们将其除以每个点的α,以获得梯度计算所需的系数。